[OS] 6. 메인 메모리 관리 (Main Memory Management)
메인 메모리 관리 (Main Memory Management) : 주소와 데이터를 관리
메모리 공간은 기본적으로 주소 (address)와 데이터 (data)로 구성되어 있다. CPU는 주소를 가지고 메인 메모리에 요청을 하거나 해당 주소에 계산 결과를 저장하며, 메인 메모리는 CPU가 요구하는 주소에 저장되어 있는 데이터를 CPU에게 전달한다.

프로그램의 빌드는 소스 파일, 목적 파일, 실행 파일 순서로 생성된다. 소스 파일(Source file)은 고수준 언어 또는 어셈블리어로 작성되며, 컴파일 단계에서 컴파일러 또는 어셈블러에 의해 컴파일 또는 어셈블하여 목적 파일(Object file)을 생성한다. 목적 파일은 컴파일된 결과 또는 어셈블된 결과를 나타내며, 링크 단계에서 링커(Linker)에 의해 라이브러리를 찾아 정보를 추가해 실행 파일(Executable file)을 생성한다. 실행 파일은 로드 단계에서 로더(Loader)에 의해 메인 메모리에 할당된다.

빌드된 프로그램은 code, data, stack 영역으로 구분된다. 단순히 생성된 프로그램은 code, data 영역만 존재하지만, 로드 단계에서 프로그램이 실행을 위해 메모리에 적재되었을 때, 운영체제에 의해 stack 영역이 추가된다.
메모리 계층 (Memory hierarchy)
메모리 계층은 각각의 특징이 있는 저장 장치를 혼용해 효율성을 극대화하는 방법이다. 메모리 계층 구조는 성능, 비용, 용량 및 접근 속도 측면에서 다양한 저장 장치들을 적절히 배치하여 최적의 성능을 제공하는 것을 목표로 한다. 메모리 매니저(Memory Manager)는 이러한 메모리 계층을 관리하는 시스템의 일부분으로, 각 계층 간의 데이터 이동과 접근을 효율적으로 관리한다.
캐시(Cache)는 메모리 계층 구조의 최상위에 위치하며, 접근 속도가 가장 빠르다. 캐시는 CPU와 가장 가까운 위치에 있어 매우 빠른 데이터 접근이 가능하지만, 용량이 제한적이고 비용이 높으며 휘발성 메모리이다. 캐시는 주로 CPU의 작업 효율성을 높이기 위해 자주 사용되는 데이터를 저장한다. L1, L2, L3 등의 레벨로 구분되며, 각 레벨은 크기와 속도에서 차이가 있다.
메인 메모리(Main Memory)는 캐시보다 느리지만, 용량이 더 크고 비용이 상대적으로 낮다. 메인 메모리 역시 휘발성 메모리로, 전원이 꺼지면 저장된 데이터가 사라진다. 메인 메모리는 운영체제와 실행 중인 프로그램이 데이터를 저장하고 접근하는 주요 공간으로 사용된다. DRAM(Dynamic Random Access Memory)이 일반적으로 메인 메모리로 사용된다.
디스크 스토리지(Disk Storage)는 메모리 계층 구조의 하위에 위치하며, 비휘발성 메모리로 데이터를 영구적으로 저장할 수 있다. 디스크 스토리지는 메인 메모리보다 훨씬 큰 용량을 제공하지만, 접근 속도가 느리고 비용이 더 저렴하다. HDD(Hard Disk Drive)와 SSD(Solid State Drive)가 대표적인 디스크 스토리지 장치이다. 디스크 스토리지는 주로 대용량 데이터 저장 및 백업 용도로 사용된다.
메모리 계층 구조를 통해 프로그래머가 사용하기 좋은 모델로 추상화하고, 운영체제를 통해 추상화된 객체를 관리한다. 프로그래머는 메모리 계층 구조의 복잡성을 신경 쓰지 않고, 운영체제가 제공하는 메모리 관리 기능을 통해 메모리에 접근할 수 있다. 운영체제는 캐시, 메인 메모리, 디스크 스토리지 간의 데이터 이동을 자동으로 처리하여 최적의 성능을 유지한다. 이를 통해 프로그램의 실행 속도를 높이고, 시스템 자원의 효율적인 사용을 도모할 수 있다.
Q. CPU가 한 번에 한 프로세스를 수행하면? : Mono-Programming
메인 프레임(mainframe)은 RAM 위의 OS에 유저 프로그램이 주소로 연결되어 존재한다. 임베디드 시스템(Embedded System)은 OS가 위치한 ROM 아래에 유저 프로그램이 주소로 연결되어 존재한다. 퍼스널 컴퓨터(personal computer)는 메인 프레임과 ROM 위 장치 관리자가 유저 프로그램 위에서 OS의 관리를 받는 형태로 존재한다.
Q. 만약 메모리 추상화를 사용하지 않는다면? : 모든 프로그램이 물리 메모리를 직접 사용
프로그래머에게 제공되는 메모리 영역은 실제 물리 메모리(0 ~ 실제 물리 메모리의 크기)로, 각 주소는 n비트로 구성된 셀(Cell)로 정의된다. 하드웨어의 도움 없이 두 프로그램이 동시에 메모리에서 실행된다는 것은 불가능하지만, 메모리의 프로세스를 이미지 형태로 디스크에 저장하고 프로그램을 메모리로 스와핑(Swapping)할 수는 있다.
메모리를 추상화하지 않는 방법도 메모리 추상화의 한 가지 방법이다. 메모리 계층 구조는 여전히 존재하며, 운영체제는 캐시, 메인 메모리, 디스크 스토리지를 물리 주소를 통해 직접 접근한다. 그러나, 물리 주소를 직접 접근하는 방법에는 Protection & Relocation 이슈가 존재한다.
P1. 프로텍션 (Protection)
한 프로세스가 운영체제나 다른 프로세스의 파티션을 침범하지 못하게 해야 한다. IBM360 모델에서는 프로텍션 코드(Protection code)를 사용한다. 프로세스의 PSW에는 4bit 키가 포함되며, 메모리를 2KB 블럭 단위로 나누고 각 블록에 4bit 프로텍션 코드를 할당한다. 수행되는 프로세스는 자신의 PSW 키와 액세스하는 블럭의 프로텍션 코드를 비교해 일치하지 않으면 트랩을 발생시킨다.
P2. 리로케이트 (Relocation)
변수 주소나 프로시저 주소에 대한 접근에 차이가 발생한다. .exe 파일을 파티션에 로드해 실행할 때, 바이너리 파일이 아닌 파티션을 기준으로 접근해야 한다. 예를 들어, 컴파일된 .exe 파일을 파티션 A와 B에 각각 로드해 실행할 때, 각 파티션을 기준으로 접근해야 한다.
IBM360 모델에서는 정적 재배치(Static Relocation)를 사용하여 프로그램이 메모리에 로드될 때 파티션을 기준으로 접근하도록 명령어를 수정한다. 이를 위해 링커가 프로그램의 어떤 부분이 리로케이트되어야 하는지 알아야 한다.
주소 바인딩 (Address Binding)
주소 바인딩은 프로세스의 논리적 주소를 물리적 메모리 주소로 연결하는 작업이다. 주소 공간(address space)은 프로세스가 메모리에 접근할 때 사용하는 주소들의 집합으로, 각 프로세스는 자신만의 주소 공간을 가진다. 프로그램이 어떤 주소를 사용해도 메인 메모리에 할당된 주소를 찾아가도록 해야 한다. 논리 주소(logical address)는 CPU에서 사용하는 주소로, 메모리 내 프로세스의 독립적인 공간이다. 물리 주소(physical address)는 메인 메모리에서 사용하는 주소로, 하드웨어에 의해 정해진 주소 공간이다.
MMU의 재배치 레지스터 (Relocation Register)
MMU의 재배치 레지스터(Relocation Register)는 프로세스의 논리 공간을 메모리의 물리 공간으로 연속해 매핑한다. 동적 재배치(Dynamic relocation)는 프로세스의 논리 주소를 메모리의 물리 주소로 변경한다. 베이스 레지스터(Base Register)는 파티션의 시작 주소를, 리미트 레지스터(Limit Register)는 파티션의 크기를 나타낸다.

- 현재 프로그램이 파티션에 로드되었을 때, 프로그램이 로드된 파티션의 크기를 리미트 레지스터의 값에 저장한다.
- CPU는 메인 메모리에서 주소가 사용 가능한지 여부를 고려하지 않고, 명시된 그대로 물리 주소를 사용하려고 한다.
- CPU가 명령어를 수행할 때마다, 프로세스가 참조하려는 주소에 베이스 레지스터의 값을 더해 수행한다 (Relocation).
- CPU가 명령어를 수행할 때마다, 프로세스가 참조하려는 주소가 리미트 레지스터의 값과 동일하거나 큰지 확인한다 (Protection).
- O: 프로텍션 바이오레이션(Protection Violation) 발생 시켜 메모리 참조를 중단한다.
- X: 프로세스가 참조하려는 주소에 베이스 레지스터의 값을 더한 값을 메모리 버스에 보낸다.
이 방식에서는 모든 메모리 참조마다 덧셈과 비교 연산이 요구되기에 비교적 시간이 오래 걸린다. 특히 덧셈 연산이 그렇다. 블로트웨어(Bloatware)는 메모리의 크기가 증가하는 속도를 소프트웨어의 크기가 증가하는 속도가 역전하는 현상을 말한다.
정적 메모리 파티션(Fixed memory partitions)은 메모리를 여러 개의 파티션으로 미리 나누고 프로세스를 할당하는 방법이다. 도착한 작업을 크기에 맞는 가장 작은 파티션에 넣는 Multiple input Queues 방식과, 도착한 작업을 수용할 큐를 하나만 배정하여 먼저 도착한 작업을 먼저 실행시키는 Single input Queue 방식이 있다.
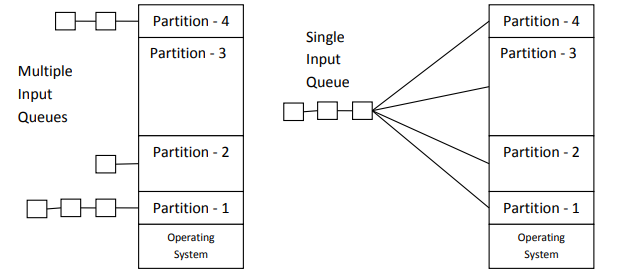
정적 메모리 파티션은 메모리가 시스템이 구동할 모든 프로세스를 적재 가능한 용량을 가져야 하나, 시스템이 구동할 모든 프로세스들이 필요한 메모리의 전체 크기는 실제 RAM 용량보다 크다. 또한, 프로그램 시작 이전에 이미 실행 중인 프로세스들이 적재되어 있을 수 있다.
스와핑 (Swapping)
스와핑은 메모리에 로드된 프로세스 중 장기간 미사용된 것을 하드 디스크에 이미지 형태로 저장하는 방식이다. 프로세스 이미지(Process Image)는 프로그램이 메모리에 로드되고 실행되어 데이터가 변경된 프로세스를 말한다. 하드 디스크에 존재하는 .exe 또는 .app 파일이 데이터가 변경됨에 따라 이를 하드 디스크의 backing store에 저장하게 된다. 메인 메모리에서 backing store로 데이터를 이동시키는 것을 swap-out이라 하고, backing store에서 메인 메모리로 데이터를 이동시키는 것을 swap-in이라고 한다.
backing store는 메인 메모리의 모든 프로세스가 swap-out될 때 데이터의 소실 없이 저장할 수 있어야 한다. 따라서, 하드 디스크에서 backing store가 할당받는 크기는 최소 메인 메모리의 크기와 같을 것으로 예상할 수 있다.

프로그램의 데이터 세그먼트가 늘어날 공간을 미리 확보하고, 각 프로그램의 세그먼트를 프로그램 텍스트, 데이터 세그먼트, 스택 세그먼트로 나누어 관리한다. 프로그램 텍스트 위의 데이터 세그먼트와 스택 세그먼트가 서로를 향해 자라게 하여 사용자가 동적으로 할당할 수 있는 힙(Heap) 영역(Room for growth)을 확보한다. malloc, calloc 등의 명령어로 힙 영역을 관리한다.
동적 메모리 파티션 (Dynamic memory partitions)
동적 메모리 파티션은 프로그램이 메모리에 로드될 때마다 파티션을 나누고 할당하는 방식이다. 운영체제가 동적으로 할당된 프로세스를 관리하며, 힙 영역이 커지므로 프로세스의 확장을 위한 공간이 할당되어야 한다.
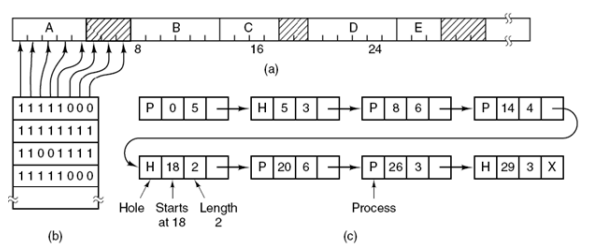
Bit Maps를 사용하여 맵에 X비트를 관장할 Y개의 할당 단위(allocation unit)를 관리한다. 단위 유닛이 메모리에 할당되어 있으면 유닛의 값을 1로, 할당되어 있지 않으면 0으로 표시하는 flag bit를 사용한다. 할당 단위가 작아지면 유닛의 개수 Y가 커지므로 맵의 크기가 커져 맵을 탐색할 때의 성능이 저하될 수 있다. 할당 단위가 커지면 유닛의 개수 Y가 작아져 비트맵의 공간이 작아지지만, 마지막 프로세스에 빈 공간이 커져 메모리 공간이 낭비될 가능성이 있다. Bit Maps의 문제점은 프로세스가 k개의 할당 단위를 요구할 때, 맵에서 k개의 0비트를 연속해서 찾아야 한다는 점이다.
Linked Lists를 사용하여 메모리의 낮은 주소부터 링크드 리스트의 노드가 있는 방식도 있다. 각 엔트리는 P(프로세스) 또는 H(홀)을 표현하는 flag, 시작 주소, 길이, 다음 엔트리를 가리키는 포인터로 구성된다. 프로세스 종료 시 Linked Lists를 업데이트하는 방법으로 종료되는 프로세스는 일반적으로 2개의 이웃을 가지며, 이웃은 다른 프로세스가 차지한 공간이거나 빈 공간일 수 있다.
X에 해당되는 엔트리를 X에서 H로 갱신하거나, 2개의 엔트리를 통합해 표현할 수 있으며, 3개의 엔트리를 통합해 표현할 수 있다.
Contiguous Memory Allocation
Contiguous Memory Allocation은 메모리에 새로 생성된 프로세스들을 위한 메모리 공간을 할당하는 방식이다. 메모리 단편화(Memory fragmentation)는 메인 메모리에 흩어진 홀들이 불연속적으로 할당된 상태를 의미한다. 프로세스 생성과 종료가 반복되면 scattered holes가 생길 수 있다. 홀(Hole)은 메인 메모리에서 프로세스가 할당되지 않은 영역이다. 외부 단편화(External fragmentation)는 프로세스를 할당할 크기가 충분하나 메모리 단편화로 할당이 불가능한 상태를 의미한다.

First-fit은 프로세스 크기보다 크거나 같은 홀을 탐색하는 순서 중에서 가장 먼저 찾은 홀에 프로세스를 할당하는 방식이다.

Best-fit은 할당할 프로세스 크기와 홀의 크기 차이가 가장 작은 홀에 프로세스를 할당하는 방식이다.

Worst-fit은 할당할 프로세스 크기와 홀의 크기 차이가 가장 큰 홀에 프로세스를 할당하는 방식이다. Best-fit을 사용하였을 때 다른 프로세스가 쓰지 못할 정도의 홀이 생겼을 때의 대안으로 사용된다.

Compaction은 메모리 여러 곳에 흩어져 있는 홀들을 강제로 하나로 병합하는 방식이다. 그러나 홀을 옮기는 오버헤드가 매우 크며, 어느 홀을 옮겨야 빠르게 합칠 수 있는지에 대한 최적 알고리즘이 존재하지 않는다.
일반적으로 할당 속도는 First-fit이 가장 빠르며, 메모리 이용률은 First-fit과 Best-fit이 비슷하다. 그러나 Best-fit을 사용하더라도, 외부 단편화로 인해 여전히 전체 메모리의 1/3 정도를 낭비하게 된다.